Concepto: En teoría de la probabilidad y estadística, la distribución de probabilidad de una variable aleatoria es una función que asigna a cada suceso definido sobre la variable aleatoria la probabilidad de que dicho suceso ocurra. La distribución de probabilidad está definida sobre el conjunto de todos los sucesos, cada uno de los sucesos es el rango de valores de la variable aleatoria.
La distribución de probabilidad está completamente especificada por la función de distribución, cuyo valor en cada x real es la probabilidad de que la variable aleatoria sea menor o igual que x.
1.Para variables discretas:
- Distribución Binomial: En estadística, la distribución binomial es una distribución de probabilidad discreta que cuenta el número de éxitos en una secuencia de n ensayos de Bernoulli independientes entre sí, con una probabilidad fija pde ocurrencia del éxito entre los ensayos. Un experimento de Bernoulli se caracteriza por ser dicotómico, esto es, sólo son posibles dos resultados. A uno de estos se denomina éxito y tiene una probabilidad de ocurrencia p y al otro, fracaso, con una probabilidad q = 1 - p. En la distribución binomial el anterior experimento se repite n veces, de forma independiente, y se trata de calcular la probabilidad de un determinado número de éxitos. Para n = 1, la binomial se convierte, de hecho, en una distribución de Bernoulli.

- Distribución de Poisson : En teoría de probabilidad y estadística, la distribución de Poisson es una distribución de probabilidad discreta que expresa, a partir de una frecuencia de ocurrencia media, la probabilidad de que ocurra un determinado número de eventos durante cierto período de tiempo. Concretamente, se especializa en la probabilidad de ocurrencia de sucesos con probabilidades muy pequeñas, o sucesos "raros".Fue descubierta por Siméon-Denis Poisson, que la dio a conocer en 1838 en su trabajoRecherches sur la probabilité des jugements en matières criminelles et matière civile(Investigación sobre la probabilidad de los juicios en materias criminales y civiles).
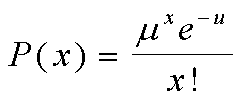
2.Para Variables Continuas:En teoría de la probabilidad una distribución de probabilidad se llama continua si su función de distribución escontinua. Puesto que la función de distribución de una variable aleatoria X viene dada por  , la definición implica que en una distribución de probabilidad continua X se cumple P[X = a] = 0 para todo número real a, esto es, la probabilidad de que X tome el valor a es cero para cualquier valor de a. Si la distribución de X es continua, se llama a X variable aleatoria continua.
, la definición implica que en una distribución de probabilidad continua X se cumple P[X = a] = 0 para todo número real a, esto es, la probabilidad de que X tome el valor a es cero para cualquier valor de a. Si la distribución de X es continua, se llama a X variable aleatoria continua.
, la definición implica que en una distribución de probabilidad continua X se cumple P[X = a] = 0 para todo número real a, esto es, la probabilidad de que X tome el valor a es cero para cualquier valor de a. Si la distribución de X es continua, se llama a X variable aleatoria continua.
En las distribuciones de probabilidad continuas, la distribución de probabilidad es la integral de la función de densidad
- Distribución Normal: En estadística y probabilidad se llama distribución normal, distribución de Gauss o distribución gaussiana, a una de las distribuciones de probabilidad de variable continua que con más frecuencia aparece aproximada en fenómenos reales.[cita requerida]La gráfica de su función de densidad tiene una forma acampanada y es simétrica respecto de un determinado parámetro estadístico. Esta curva se conoce como campana de Gauss y es el gráfico de unafunción gaussiana.La importancia de esta distribución radica en que permite modelar numerosos fenómenos naturales, sociales y psicológicos. Mientras que los mecanismos que subyacen a gran parte de este tipo de fenómenos son desconocidos, por la enorme cantidad de variables incontrolables que en ellos intervienen, el uso del modelo normal puede justificarse asumiendo que cada observación se obtiene como la suma de unas pocas causas independientes.De hecho, la estadística descriptiva sólo permite describir un fenómeno, sin explicación alguna. Para la explicación causal es preciso el diseño experimental, de ahí que al uso de la estadística en psicología y sociología sea conocido como método correlacional.La distribución normal también es importante por su relación con la estimación por mínimos cuadrados, uno de los métodos de estimación más simples y antiguos.

- Distribución Binomial:
P-20% defectuosas
n= 10
Datos:
n= numero de ensayos
p= Probabilidad de Fracaso
q= Probabilidad Fracaso
x= Numero de Exitos
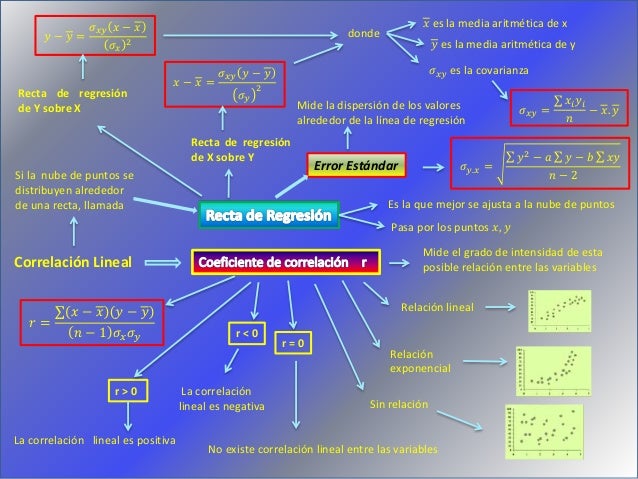
Mapa Mental

VIDEO DE EXPLICACION EN EJERCICIO Y SOLUCION CORRESPONDIENTE
- https://www.youtube.com/watch?v=unUpFZiI6DM